Gemini Context Caching Explained
GenAI Crew
Context caching in Gemini allows you to store and pre-compute context, such as documents or even entire code repositories. This cached context can then be reused in subsequent requests, leading to significant cost savings – potentially up to 75%.
For example, using Gemini 1.5 Pro, caching a full GitHub repository and then asking follow-up questions about it demonstrates this capability. Each subsequent request utilizing the same cache could cost substantially less ($0.31 vs. $1.25 per 1 million tokens, according to the tweet).
You can find a code example demonstrating this in the following notebook: https://github.com/philschmid/gemini-samples/blob/main/examples/gemini-context-caching.ipynb
Here is an image illustrating the concept: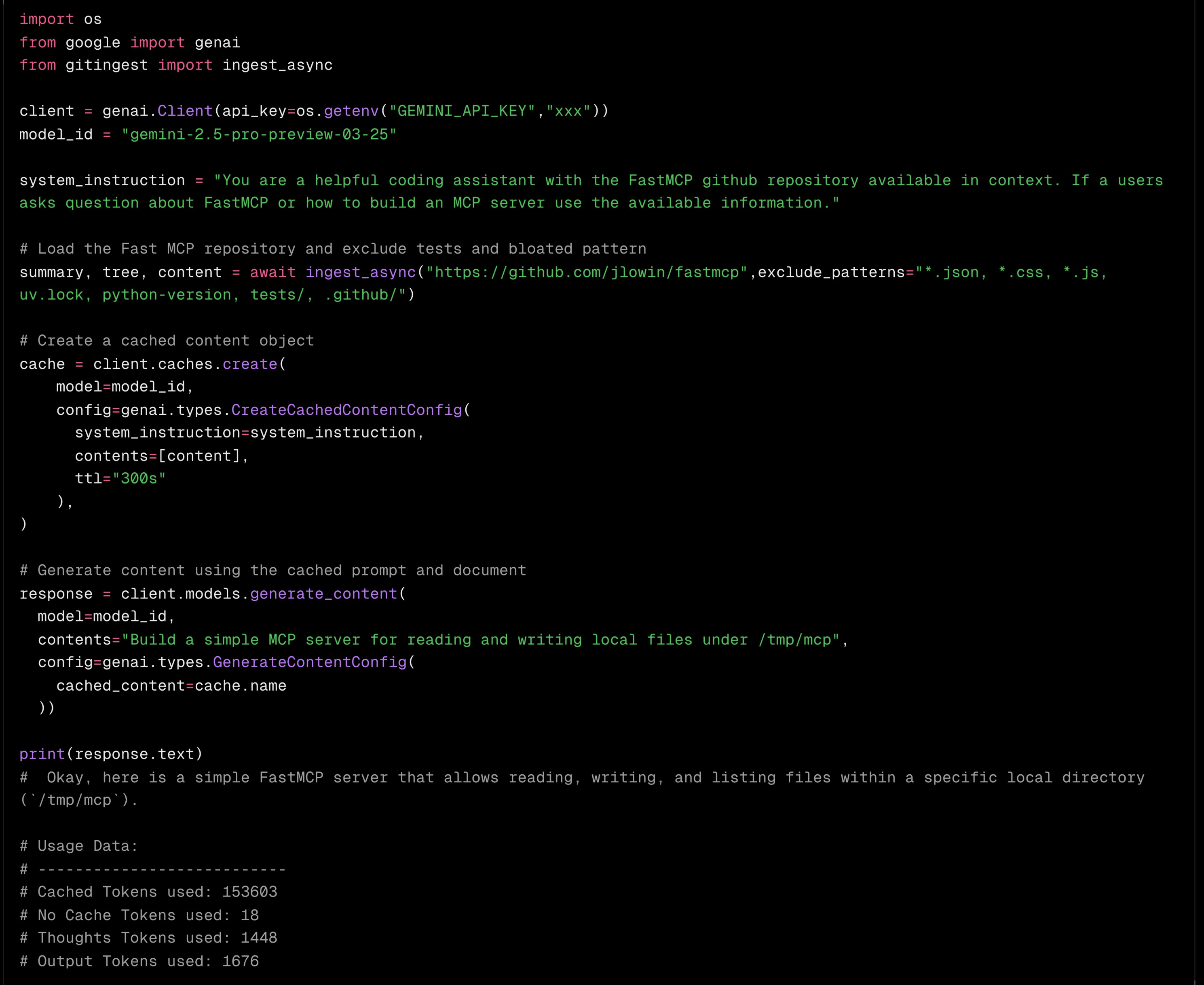
This concept is similar to OpenAI’s prompt caching feature (https://openai.com/index/api-prompt-caching/). With OpenAI, caching is reportedly automatic for prompts exceeding a certain token count (e.g., 1024 tokens), provided the context prefix remains unchanged in subsequent requests. If the prompt is inserted before the cached context, the caching mechanism might not be utilized.