Tag: AI Tools
Gradio MCP Support: Building AI Tools in Just 5 Lines of Code
Gradio Now Supports the Model Context Protocol (MCP)
Gradio, the popular Python library for building ML interfaces, now officially supports the Model Context Protocol (MCP). This means any Gradio app can be called as a tool by Large Language Models (LLMs) like Claude and GPT-4.
What is MCP?
The Model Context Protocol standardizes how applications provide context to LLMs. It allows models to interact with external tools such as image generators, file systems, and APIs. By providing a standardized protocol for tool-calling, MCP extends LLMs’ capabilities beyond text generation.
Tag: Gradio
Gradio MCP Support: Building AI Tools in Just 5 Lines of Code
Gradio Now Supports the Model Context Protocol (MCP)
Gradio, the popular Python library for building ML interfaces, now officially supports the Model Context Protocol (MCP). This means any Gradio app can be called as a tool by Large Language Models (LLMs) like Claude and GPT-4.
What is MCP?
The Model Context Protocol standardizes how applications provide context to LLMs. It allows models to interact with external tools such as image generators, file systems, and APIs. By providing a standardized protocol for tool-calling, MCP extends LLMs’ capabilities beyond text generation.
Tag: Llm
Gradio MCP Support: Building AI Tools in Just 5 Lines of Code
Gradio Now Supports the Model Context Protocol (MCP)
Gradio, the popular Python library for building ML interfaces, now officially supports the Model Context Protocol (MCP). This means any Gradio app can be called as a tool by Large Language Models (LLMs) like Claude and GPT-4.
What is MCP?
The Model Context Protocol standardizes how applications provide context to LLMs. It allows models to interact with external tools such as image generators, file systems, and APIs. By providing a standardized protocol for tool-calling, MCP extends LLMs’ capabilities beyond text generation.
A Survey of AI Agent Protocols: Framework and Future
A recent research paper from Shanghai Jiao Tong University and the ANP Community provides the first comprehensive analysis of existing agent protocols, offering a systematic two-dimensional classification that distinguishes between context-oriented versus inter-agent protocols and general-purpose versus domain-specific protocols.
The paper highlights a critical issue in the rapidly evolving landscape of LLM agents: the lack of standardized protocols for communication with external tools or data sources. This standardization gap makes it difficult for agents to work together effectively or scale across complex tasks, ultimately limiting their potential for tackling real-world problems.
Long Context Models & RAG: Insights from Google DeepMind (Release Notes Podcast)
Explore the synergy between long context models and Retrieval Augmented Generation (RAG) in this episode of the Release Notes podcast. Google DeepMind’s Nikolay Savinov joins host Logan Kilpatrick to discuss scaling context windows into the millions, recent quality improvements, RAG versus long context, and what’s next in the field.
Watch the episode:
YouTube Video
Listen to the podcast:
Apple Podcasts | Spotify
Episode Summary
- Defining tokens and context windows: What is a token, and why do LLMs use them? How does tokenization affect model behavior and limitations?
- Long context vs. RAG: When is RAG still necessary, and how do long context models change the landscape for knowledge retrieval?
- Scaling context windows: The technical and economic challenges of moving from 1M to 10M+ tokens, and what breakthroughs are needed.
- Quality improvements: How recent models (Gemini 1.5 Pro, 2.5 Pro) have improved long context quality, and what benchmarks matter.
- Practical tips: Context caching, combining RAG with long context, and best practices for developers.
- The future: Predictions for superhuman coding assistants, agentic use cases, and the role of infrastructure.
Chapters
- 0:00 - Intro
- 0:52 Introduction & defining tokens
- 5:27 Context window importance
- 9:53 RAG vs. Long Context
- 14:19 Scaling beyond 2 million tokens
- 18:41 Long context improvements since 1.5 Pro release
- 23:26 Difficulty of attending to the whole context
- 28:37 Evaluating long context: beyond needle-in-a-haystack
- 33:41 Integrating long context research
- 34:57 Reasoning and long outputs
- 40:54 Tips for using long context
- 48:51 The future of long context: near-perfect recall and cost reduction
- 54:42 The role of infrastructure
- 56:15 Long-context and agents
Notable Quotes
“You can rely on context caching to make it both cheaper and faster to answer.”
Tag: MCP
Gradio MCP Support: Building AI Tools in Just 5 Lines of Code
Gradio Now Supports the Model Context Protocol (MCP)
Gradio, the popular Python library for building ML interfaces, now officially supports the Model Context Protocol (MCP). This means any Gradio app can be called as a tool by Large Language Models (LLMs) like Claude and GPT-4.
What is MCP?
The Model Context Protocol standardizes how applications provide context to LLMs. It allows models to interact with external tools such as image generators, file systems, and APIs. By providing a standardized protocol for tool-calling, MCP extends LLMs’ capabilities beyond text generation.
Tag: Model Context Protocol
Gradio MCP Support: Building AI Tools in Just 5 Lines of Code
Gradio Now Supports the Model Context Protocol (MCP)
Gradio, the popular Python library for building ML interfaces, now officially supports the Model Context Protocol (MCP). This means any Gradio app can be called as a tool by Large Language Models (LLMs) like Claude and GPT-4.
What is MCP?
The Model Context Protocol standardizes how applications provide context to LLMs. It allows models to interact with external tools such as image generators, file systems, and APIs. By providing a standardized protocol for tool-calling, MCP extends LLMs’ capabilities beyond text generation.
Tag: Agent-Frameworks
A Survey of AI Agent Protocols: Framework and Future
A recent research paper from Shanghai Jiao Tong University and the ANP Community provides the first comprehensive analysis of existing agent protocols, offering a systematic two-dimensional classification that distinguishes between context-oriented versus inter-agent protocols and general-purpose versus domain-specific protocols.
The paper highlights a critical issue in the rapidly evolving landscape of LLM agents: the lack of standardized protocols for communication with external tools or data sources. This standardization gap makes it difficult for agents to work together effectively or scale across complex tasks, ultimately limiting their potential for tackling real-world problems.
Tag: Agent-Protocols
A Survey of AI Agent Protocols: Framework and Future
A recent research paper from Shanghai Jiao Tong University and the ANP Community provides the first comprehensive analysis of existing agent protocols, offering a systematic two-dimensional classification that distinguishes between context-oriented versus inter-agent protocols and general-purpose versus domain-specific protocols.
The paper highlights a critical issue in the rapidly evolving landscape of LLM agents: the lack of standardized protocols for communication with external tools or data sources. This standardization gap makes it difficult for agents to work together effectively or scale across complex tasks, ultimately limiting their potential for tackling real-world problems.
Tag: Ai-Agents
A Survey of AI Agent Protocols: Framework and Future
A recent research paper from Shanghai Jiao Tong University and the ANP Community provides the first comprehensive analysis of existing agent protocols, offering a systematic two-dimensional classification that distinguishes between context-oriented versus inter-agent protocols and general-purpose versus domain-specific protocols.
The paper highlights a critical issue in the rapidly evolving landscape of LLM agents: the lack of standardized protocols for communication with external tools or data sources. This standardization gap makes it difficult for agents to work together effectively or scale across complex tasks, ultimately limiting their potential for tackling real-world problems.
Failure Modes of AI Agents: Effects
Rubén Fernández (@rub) recently shared insights on a Microsoft paper about AI Agent failure modes, concerned it might not get the attention it deserves. You can find his original note here: https://substack.com/@thelearningrub/note/c-113284290
He mentioned:
I liked Microsoft’s paper about Failure Modes of AI Agents, but I think it will go unnoticed by most people, so I’ll prepare small infographics to showcase the information it contains.
The first one, some Effects of AI Agents’ failure
Tag: Ai-Ecosystem
A Survey of AI Agent Protocols: Framework and Future
A recent research paper from Shanghai Jiao Tong University and the ANP Community provides the first comprehensive analysis of existing agent protocols, offering a systematic two-dimensional classification that distinguishes between context-oriented versus inter-agent protocols and general-purpose versus domain-specific protocols.
The paper highlights a critical issue in the rapidly evolving landscape of LLM agents: the lack of standardized protocols for communication with external tools or data sources. This standardization gap makes it difficult for agents to work together effectively or scale across complex tasks, ultimately limiting their potential for tackling real-world problems.
Tag: Deepmind
Long Context Models & RAG: Insights from Google DeepMind (Release Notes Podcast)
Explore the synergy between long context models and Retrieval Augmented Generation (RAG) in this episode of the Release Notes podcast. Google DeepMind’s Nikolay Savinov joins host Logan Kilpatrick to discuss scaling context windows into the millions, recent quality improvements, RAG versus long context, and what’s next in the field.
Watch the episode:
YouTube Video
Listen to the podcast:
Apple Podcasts | Spotify
Episode Summary
- Defining tokens and context windows: What is a token, and why do LLMs use them? How does tokenization affect model behavior and limitations?
- Long context vs. RAG: When is RAG still necessary, and how do long context models change the landscape for knowledge retrieval?
- Scaling context windows: The technical and economic challenges of moving from 1M to 10M+ tokens, and what breakthroughs are needed.
- Quality improvements: How recent models (Gemini 1.5 Pro, 2.5 Pro) have improved long context quality, and what benchmarks matter.
- Practical tips: Context caching, combining RAG with long context, and best practices for developers.
- The future: Predictions for superhuman coding assistants, agentic use cases, and the role of infrastructure.
Chapters
- 0:00 - Intro
- 0:52 Introduction & defining tokens
- 5:27 Context window importance
- 9:53 RAG vs. Long Context
- 14:19 Scaling beyond 2 million tokens
- 18:41 Long context improvements since 1.5 Pro release
- 23:26 Difficulty of attending to the whole context
- 28:37 Evaluating long context: beyond needle-in-a-haystack
- 33:41 Integrating long context research
- 34:57 Reasoning and long outputs
- 40:54 Tips for using long context
- 48:51 The future of long context: near-perfect recall and cost reduction
- 54:42 The role of infrastructure
- 56:15 Long-context and agents
Notable Quotes
“You can rely on context caching to make it both cheaper and faster to answer.”
Tag: Long-Context
Long Context Models & RAG: Insights from Google DeepMind (Release Notes Podcast)
Explore the synergy between long context models and Retrieval Augmented Generation (RAG) in this episode of the Release Notes podcast. Google DeepMind’s Nikolay Savinov joins host Logan Kilpatrick to discuss scaling context windows into the millions, recent quality improvements, RAG versus long context, and what’s next in the field.
Watch the episode:
YouTube Video
Listen to the podcast:
Apple Podcasts | Spotify
Episode Summary
- Defining tokens and context windows: What is a token, and why do LLMs use them? How does tokenization affect model behavior and limitations?
- Long context vs. RAG: When is RAG still necessary, and how do long context models change the landscape for knowledge retrieval?
- Scaling context windows: The technical and economic challenges of moving from 1M to 10M+ tokens, and what breakthroughs are needed.
- Quality improvements: How recent models (Gemini 1.5 Pro, 2.5 Pro) have improved long context quality, and what benchmarks matter.
- Practical tips: Context caching, combining RAG with long context, and best practices for developers.
- The future: Predictions for superhuman coding assistants, agentic use cases, and the role of infrastructure.
Chapters
- 0:00 - Intro
- 0:52 Introduction & defining tokens
- 5:27 Context window importance
- 9:53 RAG vs. Long Context
- 14:19 Scaling beyond 2 million tokens
- 18:41 Long context improvements since 1.5 Pro release
- 23:26 Difficulty of attending to the whole context
- 28:37 Evaluating long context: beyond needle-in-a-haystack
- 33:41 Integrating long context research
- 34:57 Reasoning and long outputs
- 40:54 Tips for using long context
- 48:51 The future of long context: near-perfect recall and cost reduction
- 54:42 The role of infrastructure
- 56:15 Long-context and agents
Notable Quotes
“You can rely on context caching to make it both cheaper and faster to answer.”
Tag: Podcast
Long Context Models & RAG: Insights from Google DeepMind (Release Notes Podcast)
Explore the synergy between long context models and Retrieval Augmented Generation (RAG) in this episode of the Release Notes podcast. Google DeepMind’s Nikolay Savinov joins host Logan Kilpatrick to discuss scaling context windows into the millions, recent quality improvements, RAG versus long context, and what’s next in the field.
Watch the episode:
YouTube Video
Listen to the podcast:
Apple Podcasts | Spotify
Episode Summary
- Defining tokens and context windows: What is a token, and why do LLMs use them? How does tokenization affect model behavior and limitations?
- Long context vs. RAG: When is RAG still necessary, and how do long context models change the landscape for knowledge retrieval?
- Scaling context windows: The technical and economic challenges of moving from 1M to 10M+ tokens, and what breakthroughs are needed.
- Quality improvements: How recent models (Gemini 1.5 Pro, 2.5 Pro) have improved long context quality, and what benchmarks matter.
- Practical tips: Context caching, combining RAG with long context, and best practices for developers.
- The future: Predictions for superhuman coding assistants, agentic use cases, and the role of infrastructure.
Chapters
- 0:00 - Intro
- 0:52 Introduction & defining tokens
- 5:27 Context window importance
- 9:53 RAG vs. Long Context
- 14:19 Scaling beyond 2 million tokens
- 18:41 Long context improvements since 1.5 Pro release
- 23:26 Difficulty of attending to the whole context
- 28:37 Evaluating long context: beyond needle-in-a-haystack
- 33:41 Integrating long context research
- 34:57 Reasoning and long outputs
- 40:54 Tips for using long context
- 48:51 The future of long context: near-perfect recall and cost reduction
- 54:42 The role of infrastructure
- 56:15 Long-context and agents
Notable Quotes
“You can rely on context caching to make it both cheaper and faster to answer.”
Tag: Rag
Long Context Models & RAG: Insights from Google DeepMind (Release Notes Podcast)
Explore the synergy between long context models and Retrieval Augmented Generation (RAG) in this episode of the Release Notes podcast. Google DeepMind’s Nikolay Savinov joins host Logan Kilpatrick to discuss scaling context windows into the millions, recent quality improvements, RAG versus long context, and what’s next in the field.
Watch the episode:
YouTube Video
Listen to the podcast:
Apple Podcasts | Spotify
Episode Summary
- Defining tokens and context windows: What is a token, and why do LLMs use them? How does tokenization affect model behavior and limitations?
- Long context vs. RAG: When is RAG still necessary, and how do long context models change the landscape for knowledge retrieval?
- Scaling context windows: The technical and economic challenges of moving from 1M to 10M+ tokens, and what breakthroughs are needed.
- Quality improvements: How recent models (Gemini 1.5 Pro, 2.5 Pro) have improved long context quality, and what benchmarks matter.
- Practical tips: Context caching, combining RAG with long context, and best practices for developers.
- The future: Predictions for superhuman coding assistants, agentic use cases, and the role of infrastructure.
Chapters
- 0:00 - Intro
- 0:52 Introduction & defining tokens
- 5:27 Context window importance
- 9:53 RAG vs. Long Context
- 14:19 Scaling beyond 2 million tokens
- 18:41 Long context improvements since 1.5 Pro release
- 23:26 Difficulty of attending to the whole context
- 28:37 Evaluating long context: beyond needle-in-a-haystack
- 33:41 Integrating long context research
- 34:57 Reasoning and long outputs
- 40:54 Tips for using long context
- 48:51 The future of long context: near-perfect recall and cost reduction
- 54:42 The role of infrastructure
- 56:15 Long-context and agents
Notable Quotes
“You can rely on context caching to make it both cheaper and faster to answer.”
Tag: Release-Notes
Long Context Models & RAG: Insights from Google DeepMind (Release Notes Podcast)
Explore the synergy between long context models and Retrieval Augmented Generation (RAG) in this episode of the Release Notes podcast. Google DeepMind’s Nikolay Savinov joins host Logan Kilpatrick to discuss scaling context windows into the millions, recent quality improvements, RAG versus long context, and what’s next in the field.
Watch the episode:
YouTube Video
Listen to the podcast:
Apple Podcasts | Spotify
Episode Summary
- Defining tokens and context windows: What is a token, and why do LLMs use them? How does tokenization affect model behavior and limitations?
- Long context vs. RAG: When is RAG still necessary, and how do long context models change the landscape for knowledge retrieval?
- Scaling context windows: The technical and economic challenges of moving from 1M to 10M+ tokens, and what breakthroughs are needed.
- Quality improvements: How recent models (Gemini 1.5 Pro, 2.5 Pro) have improved long context quality, and what benchmarks matter.
- Practical tips: Context caching, combining RAG with long context, and best practices for developers.
- The future: Predictions for superhuman coding assistants, agentic use cases, and the role of infrastructure.
Chapters
- 0:00 - Intro
- 0:52 Introduction & defining tokens
- 5:27 Context window importance
- 9:53 RAG vs. Long Context
- 14:19 Scaling beyond 2 million tokens
- 18:41 Long context improvements since 1.5 Pro release
- 23:26 Difficulty of attending to the whole context
- 28:37 Evaluating long context: beyond needle-in-a-haystack
- 33:41 Integrating long context research
- 34:57 Reasoning and long outputs
- 40:54 Tips for using long context
- 48:51 The future of long context: near-perfect recall and cost reduction
- 54:42 The role of infrastructure
- 56:15 Long-context and agents
Notable Quotes
“You can rely on context caching to make it both cheaper and faster to answer.”
Tag: Failure-Modes
Failure Modes of AI Agents: Effects
Rubén Fernández (@rub) recently shared insights on a Microsoft paper about AI Agent failure modes, concerned it might not get the attention it deserves. You can find his original note here: https://substack.com/@thelearningrub/note/c-113284290
He mentioned:
I liked Microsoft’s paper about Failure Modes of AI Agents, but I think it will go unnoticed by most people, so I’ll prepare small infographics to showcase the information it contains.
The first one, some Effects of AI Agents’ failure
Tag: Infographic
Failure Modes of AI Agents: Effects
Rubén Fernández (@rub) recently shared insights on a Microsoft paper about AI Agent failure modes, concerned it might not get the attention it deserves. You can find his original note here: https://substack.com/@thelearningrub/note/c-113284290
He mentioned:
I liked Microsoft’s paper about Failure Modes of AI Agents, but I think it will go unnoticed by most people, so I’ll prepare small infographics to showcase the information it contains.
The first one, some Effects of AI Agents’ failure
Tag: Microsoft
Failure Modes of AI Agents: Effects
Rubén Fernández (@rub) recently shared insights on a Microsoft paper about AI Agent failure modes, concerned it might not get the attention it deserves. You can find his original note here: https://substack.com/@thelearningrub/note/c-113284290
He mentioned:
I liked Microsoft’s paper about Failure Modes of AI Agents, but I think it will go unnoticed by most people, so I’ll prepare small infographics to showcase the information it contains.
The first one, some Effects of AI Agents’ failure
Tag: Context-Caching
Gemini Context Caching Explained
Context caching in Gemini allows you to store and pre-compute context, such as documents or even entire code repositories. This cached context can then be reused in subsequent requests, leading to significant cost savings – potentially up to 75%.
For example, using Gemini 1.5 Pro, caching a full GitHub repository and then asking follow-up questions about it demonstrates this capability. Each subsequent request utilizing the same cache could cost substantially less ($0.31 vs. $1.25 per 1 million tokens, according to the tweet).
Tag: Cost-Optimization
Gemini Context Caching Explained
Context caching in Gemini allows you to store and pre-compute context, such as documents or even entire code repositories. This cached context can then be reused in subsequent requests, leading to significant cost savings – potentially up to 75%.
For example, using Gemini 1.5 Pro, caching a full GitHub repository and then asking follow-up questions about it demonstrates this capability. Each subsequent request utilizing the same cache could cost substantially less ($0.31 vs. $1.25 per 1 million tokens, according to the tweet).
Tag: Gemini
Gemini Context Caching Explained
Context caching in Gemini allows you to store and pre-compute context, such as documents or even entire code repositories. This cached context can then be reused in subsequent requests, leading to significant cost savings – potentially up to 75%.
For example, using Gemini 1.5 Pro, caching a full GitHub repository and then asking follow-up questions about it demonstrates this capability. Each subsequent request utilizing the same cache could cost substantially less ($0.31 vs. $1.25 per 1 million tokens, according to the tweet).
Tag: Openai
Gemini Context Caching Explained
Context caching in Gemini allows you to store and pre-compute context, such as documents or even entire code repositories. This cached context can then be reused in subsequent requests, leading to significant cost savings – potentially up to 75%.
For example, using Gemini 1.5 Pro, caching a full GitHub repository and then asking follow-up questions about it demonstrates this capability. Each subsequent request utilizing the same cache could cost substantially less ($0.31 vs. $1.25 per 1 million tokens, according to the tweet).
Tag: Prompt-Engineering
Gemini Context Caching Explained
Context caching in Gemini allows you to store and pre-compute context, such as documents or even entire code repositories. This cached context can then be reused in subsequent requests, leading to significant cost savings – potentially up to 75%.
For example, using Gemini 1.5 Pro, caching a full GitHub repository and then asking follow-up questions about it demonstrates this capability. Each subsequent request utilizing the same cache could cost substantially less ($0.31 vs. $1.25 per 1 million tokens, according to the tweet).
Tag: Collaborative-Training
Intellect-2: First Decentralized 32B RL Training Complete
Prime Intellect (@PrimeIntellect) announced the completion of INTELLECT-2, the first decentralized Reinforcement Learning (RL) training run for a 32-billion-parameter model.
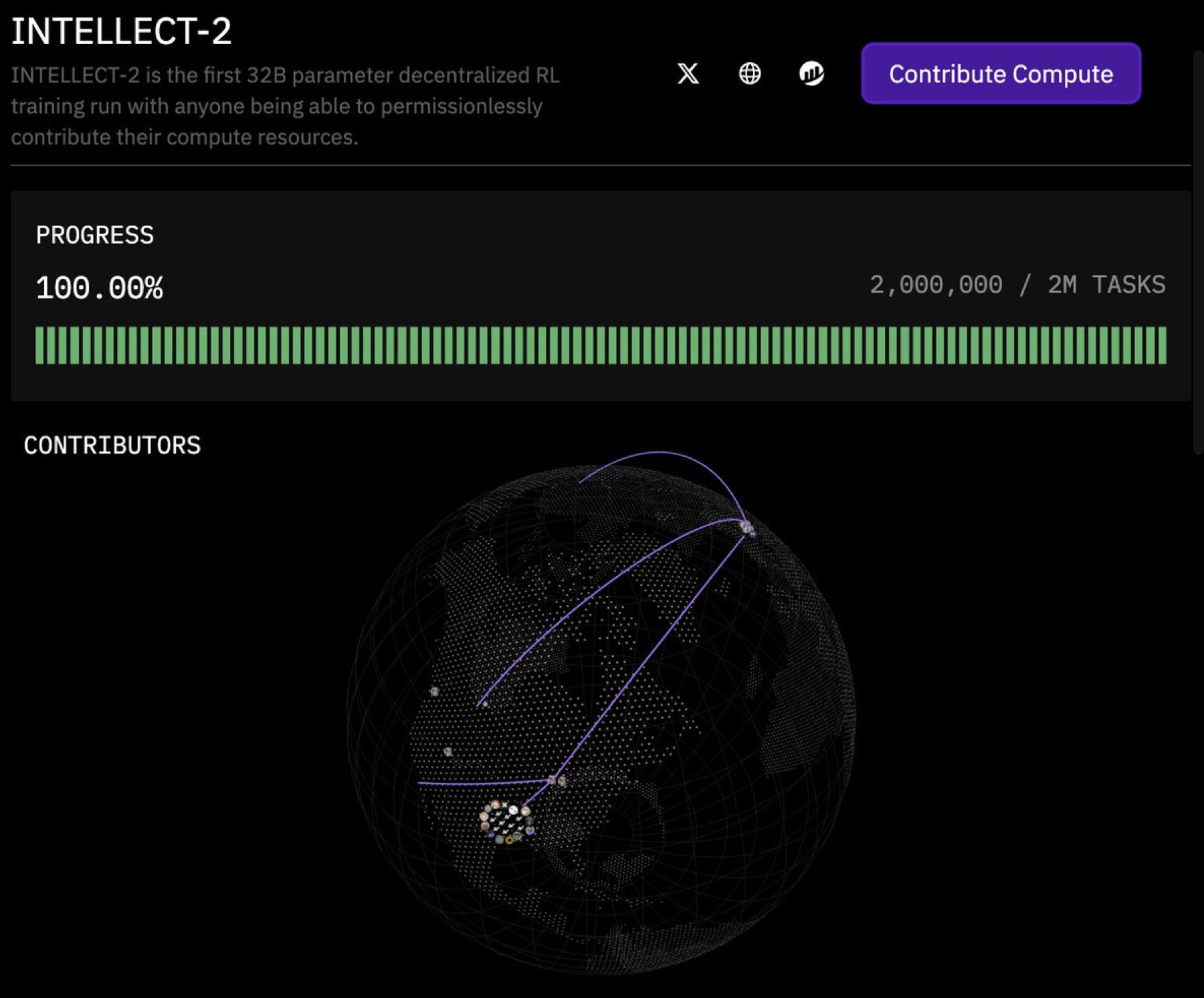
Key Points:
- Milestone: This marks the first successful decentralized RL training of a 32B model.
- Open Collaboration: The training was open to compute contributions from anyone, making it fully permissionless.
- Goal: The project aims to scale towards frontier reasoning capabilities in areas like coding, math, and science.
- Upcoming Release: A full open-source release, including model checkpoints, training data, and a detailed technical report, is expected approximately one week after the announcement (made around late August 2024).
- Community Effort: The announcement highlighted the significant contributions from various compute providers, including Demetercompute, string, BioProtocol, mev_pete, plaintext_cap, skre_0, oldmankotaro, plabs, ibuyrugs, 0xfr, marloXBT, herb0x_, mo, toptickcrypto, cannopo, samsja19, jackminong, and primeprimeint1234.
Links:
Tag: Decentralized-Ai
Intellect-2: First Decentralized 32B RL Training Complete
Prime Intellect (@PrimeIntellect) announced the completion of INTELLECT-2, the first decentralized Reinforcement Learning (RL) training run for a 32-billion-parameter model.
Key Points:
- Milestone: This marks the first successful decentralized RL training of a 32B model.
- Open Collaboration: The training was open to compute contributions from anyone, making it fully permissionless.
- Goal: The project aims to scale towards frontier reasoning capabilities in areas like coding, math, and science.
- Upcoming Release: A full open-source release, including model checkpoints, training data, and a detailed technical report, is expected approximately one week after the announcement (made around late August 2024).
- Community Effort: The announcement highlighted the significant contributions from various compute providers, including Demetercompute, string, BioProtocol, mev_pete, plaintext_cap, skre_0, oldmankotaro, plabs, ibuyrugs, 0xfr, marloXBT, herb0x_, mo, toptickcrypto, cannopo, samsja19, jackminong, and primeprimeint1234.
Links:
Tag: Large-Models
Intellect-2: First Decentralized 32B RL Training Complete
Prime Intellect (@PrimeIntellect) announced the completion of INTELLECT-2, the first decentralized Reinforcement Learning (RL) training run for a 32-billion-parameter model.
Key Points:
- Milestone: This marks the first successful decentralized RL training of a 32B model.
- Open Collaboration: The training was open to compute contributions from anyone, making it fully permissionless.
- Goal: The project aims to scale towards frontier reasoning capabilities in areas like coding, math, and science.
- Upcoming Release: A full open-source release, including model checkpoints, training data, and a detailed technical report, is expected approximately one week after the announcement (made around late August 2024).
- Community Effort: The announcement highlighted the significant contributions from various compute providers, including Demetercompute, string, BioProtocol, mev_pete, plaintext_cap, skre_0, oldmankotaro, plabs, ibuyrugs, 0xfr, marloXBT, herb0x_, mo, toptickcrypto, cannopo, samsja19, jackminong, and primeprimeint1234.
Links:
Tag: Reinforcement-Learning
Intellect-2: First Decentralized 32B RL Training Complete
Prime Intellect (@PrimeIntellect) announced the completion of INTELLECT-2, the first decentralized Reinforcement Learning (RL) training run for a 32-billion-parameter model.
Key Points:
- Milestone: This marks the first successful decentralized RL training of a 32B model.
- Open Collaboration: The training was open to compute contributions from anyone, making it fully permissionless.
- Goal: The project aims to scale towards frontier reasoning capabilities in areas like coding, math, and science.
- Upcoming Release: A full open-source release, including model checkpoints, training data, and a detailed technical report, is expected approximately one week after the announcement (made around late August 2024).
- Community Effort: The announcement highlighted the significant contributions from various compute providers, including Demetercompute, string, BioProtocol, mev_pete, plaintext_cap, skre_0, oldmankotaro, plabs, ibuyrugs, 0xfr, marloXBT, herb0x_, mo, toptickcrypto, cannopo, samsja19, jackminong, and primeprimeint1234.
Links: